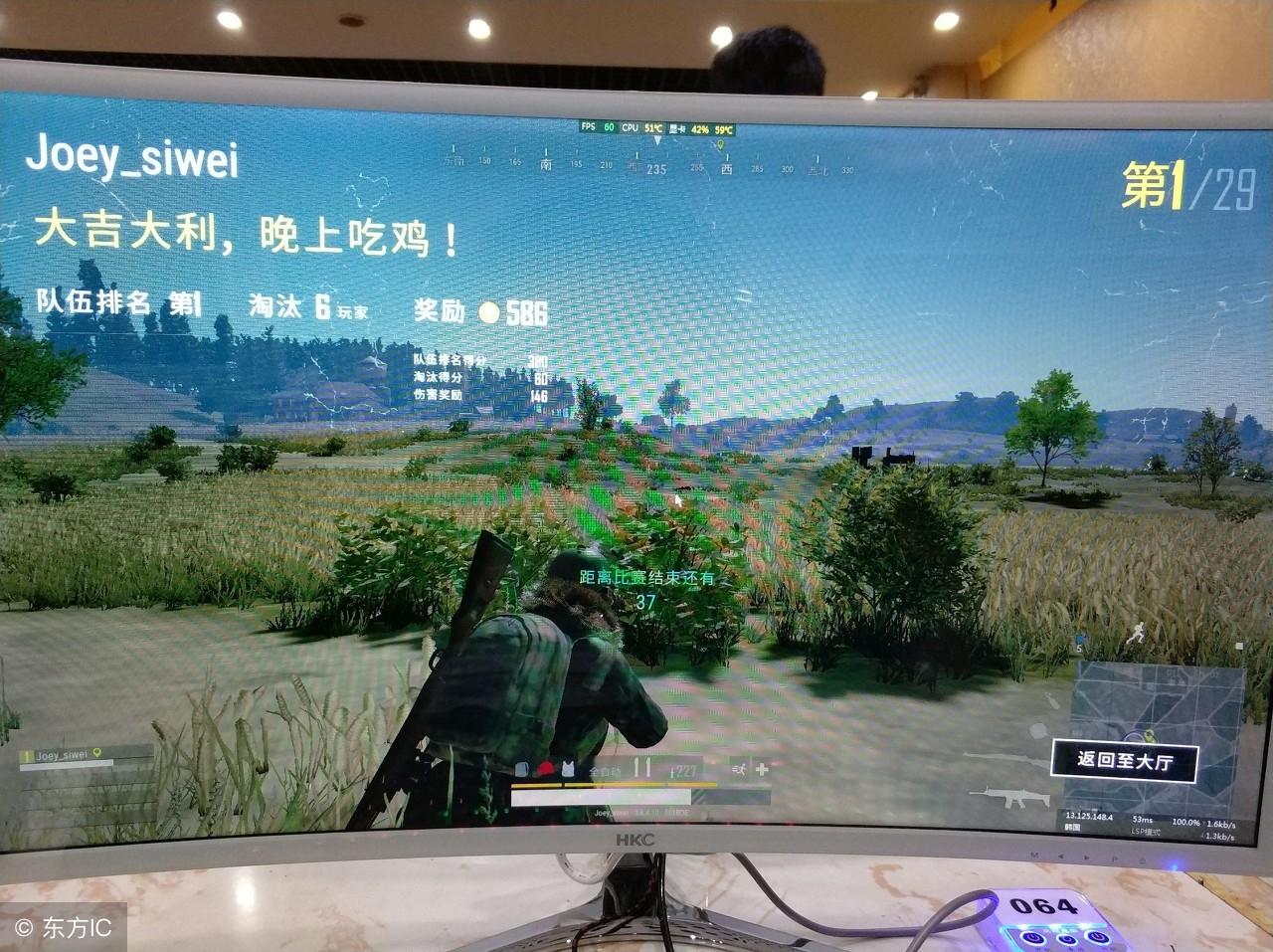
有网友质疑官方的封禁名单效果不好,不能有效地阻止作弊行为。尤其在高分段和主播局里,大家都担心游戏的公平性和竞技性会受影响。他们觉得和平精英外挂,如果作弊问题不解决好,游戏的名声和大家玩得开心程度都会受损,长远来看也会影响游戏的发展。

玩家疑虑与反思:官方应对作弊问题采取何种措施?
大家都觉得游戏里作弊太过分了,于是开始想办法解决这个问题。有些人希望官方能更狠地打击作弊行为,比如加大封号力度,这样才能保证游戏的公平竞争。另外,他们还建议在游戏里增加举报功能,让大家看到作弊就举报,一起保护好游戏环境。当然,还有人觉得官方应该升级防作弊系统,让它变得更聪明、更准,这样就能更好地发现和阻止作弊行为了。

游戏未来展望:共同打造清朗游戏环境

虽然现在《和平精英》有点作弊问题,但大家还是很看好这个游戏。相信只要官方加大打击力度,作弊情况会少很多,游戏环境秩序都会好起来。另外,大家还希望游戏公司能多听听玩家的声音,多跟我们交流,一起把游戏环境弄得更好。这样才能保证游戏长久发展,让更多人玩得开心。
外挂网站 外挂知识库揭秘:如何轻松回答问题?
在使用外挂知识库来回答问题的流程中,首要的一步就是选择相关的知识库。这个过程需要根据问题所涉及的领域或主题来进行,以确保选取的知识库能够提供与问题相关且具有价值的信息。对于不同类型的问题,可能需要借助不同来源的知识库,比如专业领域的书籍、学术论文、技术文档等,或者是互联网上特定领域的网站、数据库等。选择合适的知识库是确保外挂知识库有效性的基础。
在实际操作中,为了更精准地选择相关的知识库,我们需要对问题进行深入分析和理解。通过对问题所属领域、背景信息以及可能涉及到的专业术语等进行梳理外挂网站,可以更好地确定需要借助哪些知识库来支持问答模型的回答过程。只有选取到与问题高度相关且权威可信的知识库,才能有效提升模型回答问题的准确性和全面性。
另外,在选择相关知识库时,也需要考虑到知识库内容的时效性和更新频率。有些领域的知识可能会随着时间迅速更新,因此及时更新和维护所选取的知识库也是至关重要的。只有保证了所选取知识库内容的时效性,才能让问答模型基于最新信息来作出准确回答。
提取相关信息
提取相关信息是使用外挂知识库回答问题流程中至关重要的一环。通过有效地从选定的知识库中提取与问题相关的信息,可以为问答模型提供必要而有力的支持。这个过程通常涉及到文本分析和信息抽取等技术手段,以确保从大量信息中准确获取与问题直接相关且有意义的内容。
要实现信息提取工作,通常会运用自然语言处理(NLP)算法来处理文本数据。其中包括对文本进行分析、关键词提取、实体标注等操作,以便从海量文本中快速准确地捕捉到与问题相关联的内容片段。通过这些技术手段可以帮助问答模型更快速地理解问题,并从海量信息中迅速找到关键信息点,为后续生成答案奠定基础。
除了利用NLP算法外,在信息提取阶段还可以结合机器学习和深度学习等技术手段来优化提取效果。通过构建相应模型,并对大规模数据进行训练和调优,可以进一步提高从知识库中提取相关信息的准确性和覆盖面。这种结合多种技术手段来实现信息提取过程,有助于为问答模型提供更全面、准确且高效的支持。
整理和存储信息
在成功提取出与问题相关信息后,下一步就是对这些信息进行整理和存储。将提取到的内容整理成结构化数据,并存储在适当格式中,是为了方便后续问答模型能够快速有效地检索和利用这些信息。
整理和存储信息过程中需要考虑到数据格式化、索引建立等方面。将文本数据转化为向量化表示或其他便于计算机处理和分析的形式,可以加速问答模型对这些信息进行搜索和匹配。同时,在存储数据时也需要考虑到数据安全和隐私保护等方面,在遵循相关法律法规前提下合理设置数据访问权限。
另外,在整理存储信息时还需注意建立良好的元数据管理机制。通过为每条信息添加元数据标签或描述性信息,可以更方便地对数据进行分类、检索和管理。这样做不仅有利于加快问答模型对知识库内容进行查找,并能够有效避免信息混乱或重复利用。
与问题一起输入模型
完成了外挂知识库内容整理存储后,在回答用户提出问题时就需要将这些内容与用户问题一起输入到问答模型中。将外挂知识库中获得并整理好了的相关信息与用户输入问题相结合,并传递给问答模型进行处理和分析。
在将外挂知识库内容输入到模型之前,通常还会经过预处理步骤以适应模型输入要求。这可能包括将文本转换成张量表示、进行编码解码处理等操作,以确保输入内容符合模型接受参数格式。只有在经过适当预处理后再输入到问答模型中,才能使得模型更好地利用外挂知识库内容帮助生成精准回答。
此外,在整合外挂知识库内容时也需要考虑如何有效平衡外部知识与内部语言模型之间关系。如何权衡两者之间关联以及如何引导模型充分利用外部资源是一个值得研究探讨并不断优化完善的话题。通过科学合理设置各项参数及优化算法设计,在输入过程中充分发挥外部资源作用,并使其融入内部语言表达体系之中。
模型回答问题
经过前述步骤处理后,问答回复系统就可以根据用户输入问题以及已经整理好了并输入到系统里面去了额外背景资料,进行推断生成回复.这个阶段,模型会根据用户输入问题,结合内部语言表达系统,外部背景资料,生成最终回复结果.
在生成回复结果时,模型会结合自身所具备语言表达能力,推理能力,以及借助额外背景资料所带来更多上下文.这样一来,可以使得系统生成更加全面丰富且具备专业性质高质量回复.相较于仅仅依靠自身内部语言表达系统生成结果,利用额外背景资料可以使得回复结果更加全面周详.

同时,在生成回复结果时也需要考虑如何平衡内部语言表达系统输出结果与额外背景资料影响.如何巧妙融合两者输出结果,使得最终回复既具备专业性又易于被人类读懂是一个重要命题.在这个阶段,需要不断优化调整算法设计,提高系统生成回复结果质量.。